| |
The Text Expert offers several text conversions both in interactive form and mass processing of several files at once. The latter is described in the following text Text Converter.
The tab "Interactive" can for example be used to extract pure text from a wealth of different structured formats. Please note the difference between the words "structured" and "formatted". Structured means that the text is written in some sort of syntax, eg. "<html>...</html>". Formatted in contrast means that the text could be bold or italic. Most of the operations are only suited for and center around unformatted text. Only a few are supporting the Rich Text Format (RTF) and XAML (for programs). The result can be copied back to a text editor or word processor. That's why you can choose the result format you would like to get.
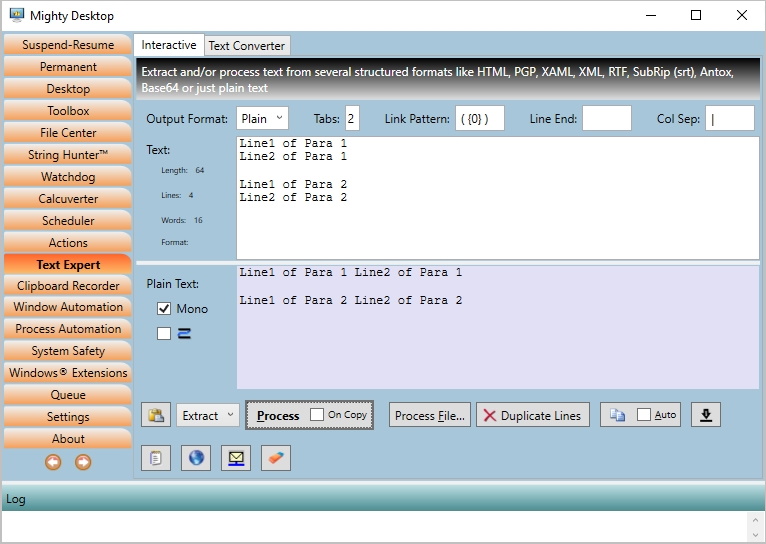
Extraction
This function tries to extract unstructured plain text out of many structured text formats.
- For Plain text: If you enter a plain text with line breaks and an empty line that represents paragraph breaks it will reassemble it into word processor paragraphs. A use case for that is if you want to copy line based text into a text processor like Write, Word, Libre Office, Open Office or alike. These programs require that each line represents a full paragraph. This function knows that text can be wrapped with a minus or hyphen character at the end of the line and that enumerations are written with a starting '-', '—', '•', '*' or '+'. Example:
Line1 of Para 1
Line2 of Para 1
Line1 of Para 2
Line2 of Para 2
will get extracted to
Line1 Line2 of Para 1
Line1 Line 2 of Para 2
The operation is aware of indentation depths and recognizes separation lines (which means lines filled with the same character for at least 3 times, eg. "********") . You can input a whole text and it will either prepare it for pasting into a word processor, or if you select another 'Output Format', will produce an RTF or XAML (used by programmers). The RTF is also a good base for pasting into a word processor.
-
HTML: HTML can be converted to plain text. A pattern can be specified for how embedded links should be presented. If you enter just a web link (i.e. https://www.atlas-informatik.ch) the content of the page at this location will be downloaded and converted. As an example this conversion can help you if you have a web page that shows some text that you want to copy out but the clipboard copy function is disabled. Just use the function of the browser to display the page source code (some browsers have it in their right click menu) or save the file locally. If you manage to see the text in HTML format you can convert it to plain text with this function.
-
XML: Plain text can be extracted from XML in a similar way as HTML above
-
XAML: This is help for WPF developers: When you edit text in the Visual Studio Designer your text will miraculously be converted by Visual Studio into XAML elements like "<Run Text=....>". Mighty Desktop can restore the text in its previous compact form without all the run tags. And it can also write the XAML representation. For the latter you need to switch the 'Output Format' to 'XAML'.
- RTF: The content of an RTF file can be extracted resp. converted to a pure text which is visually looking as identically as possible. Indentation and nested bulleting is supported. A whole line in a font >= 15 pt will be interpreted as document title, >= 14 as a chapter title and be underlined by '=' resp. '-'
It's also supported into the opposite direction: You can input a plain text with indentation and bulleting (which is by the way much quicker than editing formatted text), and if finished convert it to a formatted RTF text:
Para 1
- List Item
- List Item
Continuation of Para 1
Para 2
Actually this text was also created like this in a first step. In addition the notation " *BoldWord* " can be used to make a word bold and the passage "##Word_Definition" is converted to `Word Definition` (backward quotes and bold).
Note that the .NET Framework has several bugs in this area. For example in the RichTextBox the margins and indentations can look quite different from those in the exported file, especially when lists are nested. Also, different word processors interpret RTF in different ways. The same RTF file can look quite different. Wordpad for example has a bug which indents the first list item sometimes too much and you can't counteract it in any way interactively. LibreOffice Writer can also handle RichText in general very well but has also some minor displaying problems.
Other processings
Rewrap Paragraphs : This highly sophisticated operation can rewrap the paragraphs of a text to any width you like. You can enter the preferred width in the Settings tab. It does about the same as a text processor but it does it for plain text. It can do this for unstructured text (where empty lines are separating the paragraphs) as well as for usual programming language remarks enclosed in tags like "<summary>", "<remarks>", "<!-- .. -->" , "/*..*/" and behind "//". If a formatted text like RTF is given it will first extract the unformatted representation with the Extract function described above and then rewrap the text. Separation lines of various type as well as underlines of chapter titles are recognized (underlines are made from the same character and length at least 3). The indentation of the paragraph will be recognized (using tabs, blanks, "- ", "* ", "· ", "• ", "+ ", "a)", "1)", "1.") and reproduced for the output. When a hyphen ('-') is at the end of a line it will automatically join the separated words to one (Mighty Desktop knows some of the most used exceptions) and these break points will be remembered and used if a break is necessary in the output. Bottom line: you can input paragraphs with all their tags and get them back rewrapped wonderfully.
-
The case of each word can be changed to lowercase if it's entirely in uppercase. Exceptions are words at the start of each sentence and paragraph as well as some special words that always written in uppercase as for example all currency symbols. A list of all known words that are in uppercase is downloaded from the Atlas server daily. A use case for this could be to use it on contract documents (Terms and Services) which use uppercase extensively to make it nearly unreadable. Counter this trick with this conversion from now on!
-
Sort: The lines of the text can be sorted in a lexicographically correct order. Other than in some third party tools this is based on the full UNICODE dictionary which means it works correctly for all characters in the world , including all the special ones like Umlauts, diacritic characters and any symbols. Lowercase letters are sorted - as they should - directly behind the capital ones, for example Abc, Äbc, abd, Bcd (different for example from Notepad++).
-
Duplicate lines can be removed. The necessary comparison can either respect or ignore whitespace at the start and end.
-
Invisible lines can be removed. "Invisible" means filled with only so called `Whitespace` characters like blanks, tabs or such that look like a blank.
-
Invisible characters at the start and/or end of all lines can be removed
-
To and From HTML notation: If you have for example a string like "https://ä" browsers will convert that into language independent symbols. In this example it would produce "https%3A%2F%2Fä". Mighty Desktop (in fact all Atlas apps) have a special programming that ensures that umlauts like "äöüÄÖÜ.." will get translated in the "&abcd;" notation and not just in the less clear "&#nn;" notation (ie. "ä" will be represented by "ä" (=a-umlaut) and not the cumbersome "ä"). The purpose of a conversion in the opposite direction is mainly to bring back an HTML text into human readable form.
-
To and From URL notation: The web addresses in HTML are called URLs. In these, not only umlauts but often common characters like space, colon, slashes, etc. are converted to a percent notation. "https://My website" would become "https%3A%2F%2FMy+website". The purpose of a conversion in the opposite direction is mainly to put an Internet link back into a human-readable form.
-
Quote C / Quote DOS / Unquote: This is for programmers. It will convert any string to be used to a C, C#, Java programs or DOS shell and also in the other direction.
-
Escaping or unescaping a Regular Expression string: All characters in a string that have meaning in the syntax of a Regular Expression must be escaped to avoid a conflict. These functions can do it in both directions.
- Swap Assignments: If you have C#, C++ or C source code which assigns many fields from one class to another you may need to assign them back when a dialog closes. Example:
| dialog.A = myObj.A; |
|
myObj.A = dialog.A; |
| dialog.B = myObj.B; // Comment |
|
myObj.B = dialog.B; // Comment |
| dialog.C = myObj.C; |
|
myObj.C = dialog.C; |
It will keep the indentation of the line, the comments and also the amount of blanks left and right of the equal sign. Also, equal signs embedded in strings or chars are not a problem.
-
Reduce Blanks To One: Shrinks passages of multiple blanks to a single one. Blanks that are used to indent lines are not touched. This is commonly used for texts that result from OCR scanning. They tend to insert more than one blank between words. Not so funny to reduce them by hand.
-
English dates to regional: All dates in the english format are identified (eg. '12/31/2020') and converted to the regional form used currently in Windows (eg. '31.12.2020'). All parts are recognized in short or long. This is a heuristic, so please check the output.
-
Single To Multicolumns: Some Websites present their tables in multiple columns but if you copy them to the clipboard you only see a one-dimensional vertical list of columns which isn't very useful. This function converts it back to the original multicolumn table after you entered the number of columns and in which direction they were read out. You can also omit columns.

- Table Listing to Table: When a table was listed from top left to bottom right in the format 'ColumnName: Value', this function will recreate the two-dimensional table. The table can get fairly wide since every column is as wide as its longest value. Each line that is not a pair will be considered to be separating one table row from the next. The blank after ':' is optional. The input in 'Line End' will be used to separate lines and 'Col Sep' columns. Example:
Child Name: Melissa
Parent Name: Harry
Child Name: Peter
Parent Name: Steve
After using 'Table Listing to Table' (a monospaced font should be used):
Child Name Parent Name
---------- -----------
Melissa Harry
Peter Steve
If 'Col Sep' is ',' or ';' a CSV notation will be produced where the first line is the header:
Child Name;Parent Name
Melissa;Harry
Peter;Steve
-
Extract Columns of Fixed Width Table: If you have a table like the one above with 'Child Name' and 'Parent Name' you can extract columns out of it or swap them.

To get the required column numbers you can either select some text in the box 'Text', which will then update the statistics below, -or- paste the text in a text editor like Notepad++ and take a look at the column number displayed in the status bar at the bottom. The required numbers are 1-based. If they are right of the line end it will only extract what's there . The box 'Line End' and 'Col Sep' will be used for joining the picked columns resp. lines.
-
Windows Installer product key name to GUID and vice versa: These conversions are more interesting for supporters and programmers. When software is installed using the standard Windows Installer, some data in the Windows registry is stored in a subkey with the GUID of the product. Some other data is in a subkey with a computed variant of the GUID. This conversion creates the computed variant and vice versa. If a GUID is converted you can also input a whole product registry path. The GUID at the end will automatically be extracted.
- Spell checking: If you right-click in the box 'Text' you can activate the Spell Checker and easily correct typos. For more information see the corresponding chapter in General Features.
Paste operation specialties:
- Field 'Tabs': Tabulators in the pasted text will be interpreted as this amount of blanks. In all other areas of Mighty Desktop the tab width defined in the Settings will be used, but not here. Note: Since a .NET textbox doesn't support tab widths other than 8, Mighty Desktop is forced to replace tabs by blanks if the width is not set to 8. Change this number to 8 to keep TAB characters when pasting.
- If multiple files of a folder on the Windows Desktop are selected and dropped into 'Text', a textual list of the pathnames is produced. By default the names are separated by a comma, but you can also get newlines by holding [Alt]. Blanks inside a name will trigger quoting.
The output text can be viewed optionally in a monospaced font (where each character is of the same width) to see indentations and underlinings more clearly.
Note that the export functions are sensitive to the extension of the filename you specify for your file and you can control the resulting format with this.
Infos: Left of the output some useful statistics about the input text are displayed, which is essential for people who write chats and articles:
- The number of words
- The number of lines
- The number of characters
Text Expert features some help for mass operations:
- You can instruct Text Expert to start processing automatically each time you copy a text to the clipboard (checkbox 'On Copy').
- You can instruct Text Expert to automatically copy the output to the clipboard each time you press the 'Process' button (by checking 'Auto' right of the 'Copy' button). This will save one keystroke resp. mouse click.
- If you activate both boxes you can use Text Expert as a helper in the background while using third party applications. For example you could set the processing mode to 'Sort', then switch over to your text processor app, select some lines, and copy them to the clipboard. Text Expert will sort them lexicographically correctly and copy the result to the clipboard from where you can finally paste it to replace the unsorted list. Only two keystrokes, easy peasy. I use this system often when editing texts in Notepad++ to rewrap paragraphs.
|